NLP中GlobalMaxPooling的可视化理解
最近的一些在NLU中可视化实验总结,包括AttentionPooling1D、GlobalMaxPooling1D的物理意义。
在进行NLU任务时,我们常常通过词(或字)向量序列通过Pooling的方法获得局向量(或文档)的表示。这样的Pooling方法常见有:
- AveragePooling
- MaxPooling
- MinVariancePooling
- AttentionPooling
- SIF
- TF-IDF作为权重对向量序列进行加权平均
- 等等
以上方法都是无监督,Pooling消耗资源极小。考虑对NLP的序列都是不定长,以上方法都应该支持Mask。以上相关实现和实验可参看sentence-embedding。
然而,我们面临一个疑问,以上Pooling方法是否可理解?这里我们不深入探讨“可理解”是什么?直观点,以上Pooling方法是否真的捕获了对下游任务相关的信息。Pooling过程把词向量序列Aggregation成一个定长向量,这个过程必然有大量的信息丢失,那么Pooling有效必须要保留对下游任务有用的信息而过滤无用的信息。
GlobalMaxPooling1D可视化理解
GlobalMaxPooling1D直觉上很难理解,因此很有必要通过可视化理解其作用原理。一个词向量序列可以用矩阵表示,其维度为(maxlen, hdims),MaxPooling操作后,变为向量,可以看做句向量的表示,其维度为(1, hdims)。hdims每个值对应着某个词向量的最大值,把其作为该词在下游任务中重要性的权重,并通过可视化来观察是否具有预期的效果。
GlobalMaxPooling1D原理示意图,

Embedding中的每一维可以当做是隐含的主题,当然这种主题并不像主题模型一样直观。GlobalMaxPooling1D要做的事情则是词向量序列中最显著的主题,也就是$[e_{21}, e_{42}, e_{53}, e_{64}]$向量。然后我们此向量中元素取值作为该元素所对应的字的重要性权重,如$e_{53}$表示“淇”的重要性权重,如上图所示。
实现
MaskGlobalMaxPooling1D的实现和字权重计算方法,
1 | class MaskGlobalMaxPooling1D(tf.keras.layers.Layer): |
可视化效果
输出的权重$w$作为文本的重要性权重,根据权重的大小渲染文本的颜色深浅,颜色越深越红,重要性越大,

这里可视化使用红色系colormap,颜色越深代表权重越大,反之则越小,如下:
下面是文本分类任务的可视化,文字颜色越红越深字权重越大。分类问题效果一:

分类问题效果二:
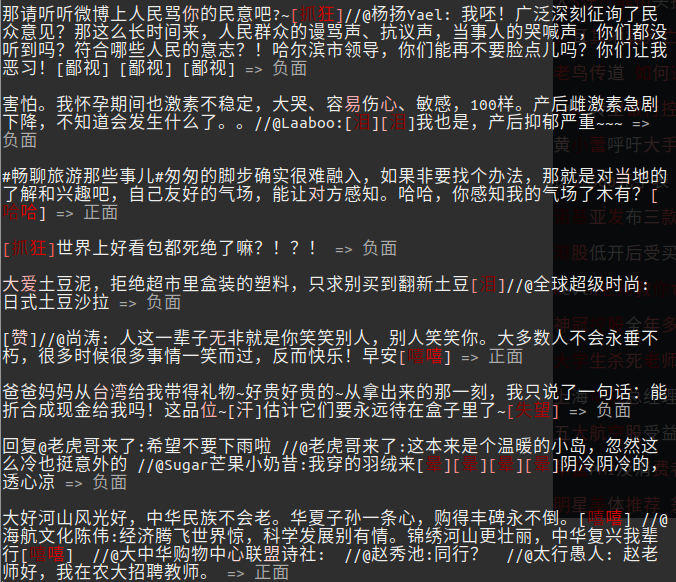
分类问题效果三:

分类问题效果四:

可以看到,MaxPooling在文本问题上也是能够定位到关键信息作为分类依据。Pooling后的句向量的每个元素能够反映其所对应的字或词的重要性。
另外,可以从主题强度来理解,词向量的每个维度代表一个隐主题,其值代表主题强度。
应用于数据扩充
既然以上方法能够定位关键字句,那么它可以作为数据扩充方案:新样本的构造来自原原本中关键字句的替换与删减。
从另外一个角度看,这似乎是对抗样本生成的一种方案。
代码分享
以上实验和可视化源码可参看:text-globalmaxpool-visualization
类似的实验还有attentionpooling,源码可参看:text-attentionpooling-visualization
总结
实验表明,这两种方法都可以捕获句子中的关键信息。然而从可视化角度看,以上方法及其相关改进都是“入侵式”,即为了获得上述可视化效果,模型上强迫你使用GlobalMaxPooling和AttentionPooling等组件。
后续更新一种新方法:integrated-gradients,它是一种比较通用的可视化方法来理解神经网络在具体任务上的表现。
转载请包括本文地址:https://allenwind.github.io/blog/13105
更多文章请参考:https://allenwind.github.io/blog/archives/