概率图模型系列(1):朴素贝叶斯分类器
本篇是概率图模型系列的第一篇,首先介绍朴素贝叶斯分类器和Logistic模型。
概率图模型,由节点和边描述,使用观察节点表示可观察的数据,隐含节点表示潜在的信息或知识,而边可以分为有向边与无向边,表示数据与知识之间的概率关系。简而言之,点表示知识,边表示知识之间的概率关系。
概率图只是一种形象的说法,即便没有图这个形象的东西,我们依旧可以很便捷地建立概率模型,因此,我们这里强调,图是至于人的直观来说的,我们应该更关注模型背后的概率思想或信息论视角理解模型。
接下来预计写一系列关于图模型的文章,包括朴素贝叶斯模型、最大熵模型、隐马尔可夫模型(HMM)、最大熵马尔可夫模型(MEMM)、条件随机场(CRF)、主题模型等等,当然视时间而定更新。
贝叶斯网络与马尔可夫网络
概率图模型由节点和边构成。其中节点对应着随机变量分为隐含节点表示知识和观测节点表示数据;边对应着随机变量的依赖或相关关系分为有向边表示单向的依赖关系和无向边表示相互依赖关系。
概率图模型分为两大类:
- 贝叶斯网络(Bayesian Network)用一个有向无环图(DAG)结构表示
- 马尔可夫网络(Markov Network)用一个无向图的网络结构表示
因此,概率图模型可以简单概况为:
- 节点:观察节点,表示数据;隐含节点,表示潜在知识
- 边:有向边,单向依赖,箭头指向的节点依赖发出节点,即贝叶斯网络;无向边,互相依赖,即马尔可夫网络
下图概况常见的图模型(来自《统计自然语言处理》):
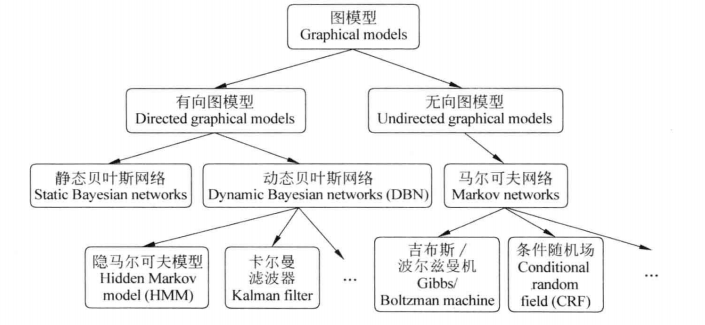
概率图模型中最基本的两个模型是Logistic模型和朴素贝叶斯模型,接下来一一介绍。
生成式模型和判别式模型
概率图模型可以分为生成式模型和判别式模型。假设可观测到的变量集为$X$,需要预测的变量集为$Y$,那么生成式模型则是对联合概率分布$P(X, Y)$进行建模,在获得$X$的情况下,推断$Y$只需要计算
生成式模型的代表有朴素贝叶斯分类器、HMM、ngrams语言模型等等。生成式模型认为$X$由$Y$决定。
而判别式模型则是直接对
进行进行建模,代表模型有最大熵模型、CRF、MEMM以及大多数深度学习建模模型。这类模型认为$Y$由$X$决定。
贝叶斯公式
回想贝叶斯公式,可以参考过去文章神经的贝叶斯公式,这里简单讲讲,
平淡无期却威力无穷。其背后的意义是,
贝叶斯公式写成分类器的形式,
其中$p(C_{k})$为先验分布,条件概率$p(\mathbf {x} \mid C_{k})$为似然。$p(\mathbf {x} )$为证据。
朴素贝叶斯分类器
朴素贝叶斯模型可以见到地理解为,
贝叶斯公式不难写成分类器的形式,根据特征$\boldsymbol{x}$推断样本所属的类别$C_{k}$,
最大化后验概率获得所属类别,
朴素贝叶斯的学习需要估计$p(C_{k})$和$p(\mathbf {x} \mid C_{k})$,使用极大似然估计(MLE)后续会提及。注意到分母部分$p(\mathbf {x} )$不参与分类计算。朴素贝叶斯之所以朴素是因为这里引入,特征条件独立假设,
$p(x|C_{k})$示意图,
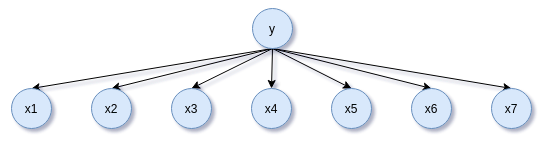
因此,朴素贝叶斯分类器的目标函数是后验概率最大化,分类器可以写成,
就是说在特征 $\boldsymbol{x}$ 条件下,类别为 $C_{k}$ 的概率。然而,这个计算还是很难的,为此我们弱化一下模型,认为特征 $\boldsymbol{x}$ 的各个分量是条件独立的,这也是朴素的来源。为此,根据贝叶斯公式和特征条件独立假设,有如下推导,
估计$p(C_{k})$和$p(\mathbf {x} \mid C_{k})$,使用极大似然估计(MLE)。这么简单的模型,但是威力巨大,早期 Google 使用朴素贝叶斯方法进行邮件分类。
参数估计与平滑化
使用极大似然估计来估计来自贝叶斯公式的模型的参数,熟悉贝叶斯统计的同学可能觉得这操作比较奇诡。我想,这就是朴素贝叶斯的名称来源之一。
贝叶斯分类器可以使用最大似然方法估计$p(C_{k})$和$p(\mathbf {x} \mid C_{k})$。其中先验概率$p(C_{k})$的估计如下,
条件概率$p(\mathbf {x} \mid C_{k})$估计如下,
然而,最大似然方法估计可能会出现概率值为0的情况,进而影响后验概率的计算,影响模型性能。为此,可以在最大似然方法估计的基础上引入参数平滑。
先验概率$p(C_{k})$加$\lambda$平滑后的估计如下,
当$\lambda=1$时,称为拉普拉斯平滑,这也是最简单最常用的平滑方法。如果$\lambda=0$则退化成极大似然估计。
条件概率$p(\mathbf {x} \mid C_{k})$加$\lambda$平滑后的估计如下,
同样,如果$\lambda=0$则退化成极大似然估计。
高斯贝叶斯分类器
如果似然函数$p(\mathbf {x} \mid C_{k})$为,
那么朴素贝叶斯分类器称为高斯贝叶斯分类器。
Multinomial naive Bayes
朴素贝叶斯分类器可以推广到多项朴素贝叶斯(Multinomial naive Bayes)分类器。多项分布下,似然$p(\mathbf {x} \mid C_{k})$为,
然后套用上面的推导并取对数,
注意一些干扰项,其实推导是不难的。看明白后,你会发现,什么,这不就是一个线性分类器吗?
总结
本文是概率图模型系列的第一篇,主要讲述概率图的基本概念以及两个模型:朴素贝叶斯分类器和Logistic模型。下篇计划写最大熵模型。
参考
[1] 《统计学习方法》
[2] https://en.wikipedia.org/wiki/Naive_Bayes_classifier
[3] https://scikit-learn.org/stable/modules/naive_bayes.html
[4] 《统计自然语言处理》